
Syncing Wearable Sensor Data Using Audio Anchors
Measuring aggregate Galvanic Skin Response (GSR) for shared events like the Super Bowl has traditionally been a “watch party” problem: bring participants into one room, expose everyone to the same stimuli, and log everything against a single master clock.
COVID-19 changed that. NeuroLynQ Home shifted data collection into participants’ living rooms—but remote collection introduced a new bottleneck: synchronization.
The Problem: The “Audio-Forensics” Bottleneck
Without a shared environment or shared clock, aligning GSR streams across dozens of households required an awkward manual workflow:
- Record ambient room audio using a separate laptop (in addition to the wearable).
- Identify a usable sync point in the broadcast (e.g., a referee whistle or a repeated phrase).
- Manually compute offsets for each participant by listening to the audio, finding the moment, and applying a time shift to the sensor data.
This approach works, but it’s not great:
- It adds extra hardware and setup friction for participants.
- It introduces human variability and error.
- It doesn’t scale well when cohorts get large.
The Solution: On-Device Audio Anchoring
Shimmer3R can log short audio anchors to SD via its onboard microphone, enabling scalable post-hoc synchronization without manual time alignment or additional capture hardware.
We propose Audio Anchoring:
- GSR logging
Record physiological data to SD as normal. - Audio beacons
Record short, timestamped audio snippets periodically (e.g., every 5 seconds, or another cadence depending on storage/power constraints). - Automated offset detection
Use the audio snippets to compute the temporal offset between each participant’s recording and a reference track (e.g., a master broadcast capture), then shift the sensor timeline automatically.
Proof of Concept: MFCC-Based Matching
To automate alignment robustly in real-world audio, we propose using Mel-Frequency Cepstral Coefficients (MFCCs).
For the proof-of-concept:
- We used a 1-minute reference audio recording.
- We used a separate 5-second snippet recording of the same content.
- We injected noise into the last 1–2 seconds of the snippet to simulate household conditions.
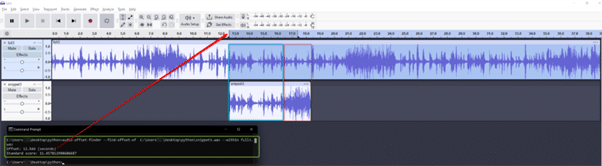
Using audio-offset-finder, the algorithm correctly identified the snippet’s offset in the reference track. When aligned in Audacity at the computed offset, the snippet and reference line up well despite the injected noise (see screenshot).
Proposed Workflow
- Capture
Participants wear Shimmer3R at home. No external laptop is required. - Extract
After the session, download GSR data and audio anchors from the SD card. - Align
Run audio offset detection to compute each device → reference offset, then shift each participant’s sensor timeline automatically. - Analyze
Aggregate synchronized GSR streams to visualize cohort-level response over time (ads, key plays, halftime, etc.).
Limitations and Practical Notes
Audio is powerful, but it’s not magic:
- Time-of-flight effects: Audio arrives at slightly different times depending on distance from the TV/speaker (typically milliseconds to tens of milliseconds in household environments). For slower-changing signals like GSR—and HR trends—this level of error is usually acceptable.
- Clock drift: For long sessions, device clocks can drift, causing offsets to change slowly over time. Periodic anchors (rather than a single start marker) can be used to estimate and correct drift if required.
- Quiet environments / low TV volume: Anchor quality depends on capturing enough broadcast audio content.
- No real-time visibility: Audio anchoring is inherently post-hoc. You don’t get live data during the event. However, it can complement NeuroLynQ’s radio-based streaming workflows: streaming supports real-time monitoring but can be susceptible to dropouts, while audio anchoring prioritizes capture reliability and simpler setup at the cost of real-time access.
Future Integration
This approach isn’t limited to GSR or NeuroLynQ. Any scenario involving multiple devices that need post-hoc alignment—IMU, ECG/EMG, multimodal studies—can benefit from audio anchors when a shared hardware trigger isn’t available.
If you’d like to see this workflow integrated into Consensys or NeuroLynQ, please register your interest or contact us.